
Note
François Chollet rightfully said that people often underestimate the impact of scikit-learn. I give here a few illustrations to back his claim.
A few days ago, François Chollet (the creator of Keras, the library that that democratized deep learning) posted:

Indeed, scikit-learn continues to be the most popular machine learning in surveys:
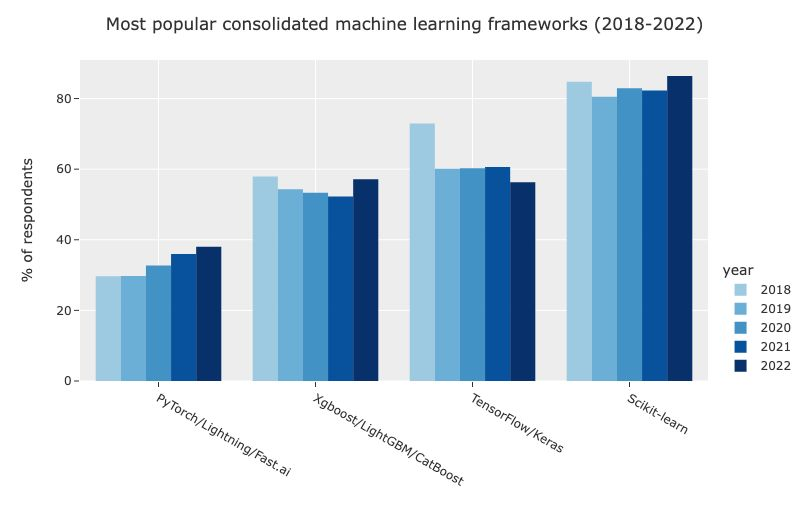
Most popular machine-learning framework, according to a Kaggle survey
Note
Scikit-learn is probably the most used machine-learning library
This popularity is sometimes underestimated as scikit-learn is a small player in terms of funding and size of the team, in particular compared to giants such as tensorflow and pytorch. Size is limited by nature of the project, based on a community without a strong commercial entity backing the project.
We target different technology than tensorflow and pytorch: we have by design let the big players focus on deep learning, which demands much more resources. Rather, we have focused on classic machine learning, believing that it serves other important needs. While such technologies make less the news, they are used a lot, and scikit-learn is massively used:
 |
 |
 |
 |
 |
 |
By not focusing on deep learning, does scikit-learn risk to become outdated? Surveys show that simple models such as linear models or models based on trees (including boosting) are actually the most used models:
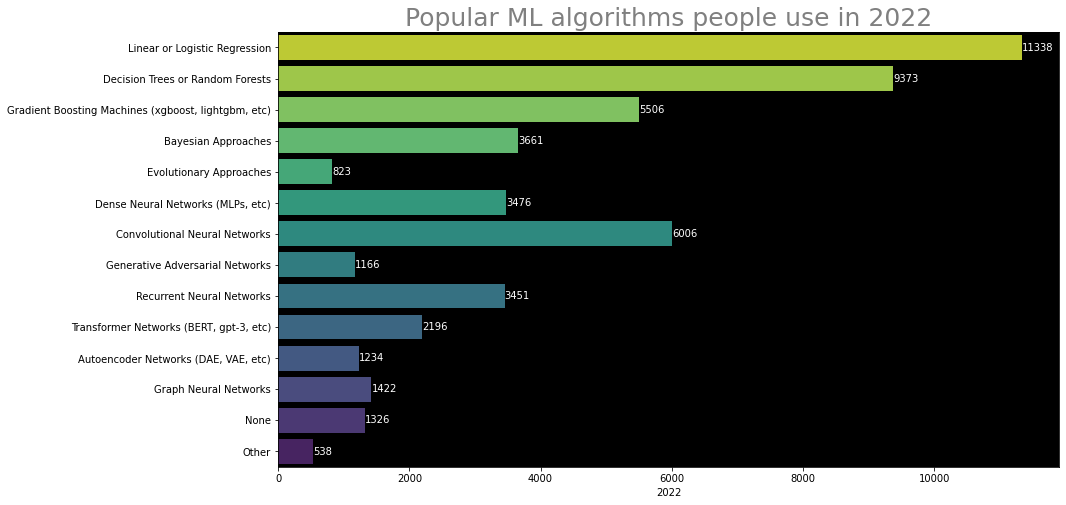
Most popular machine learning algorithm, according to a kaggle survey (apologies for the small fonts on the figure, I did not generate it)
Note
Gradient Boosted Trees is a good go-to model
There is a lot of hype surrounding deep learning, but it is most often not the right tool do tackle tabular data. Tabular data has different properties than images or text: it comes with heterogeneous columns which make sense by themselves, and tree-based models have the right inductive bias [Grinsztajn et al 2023].
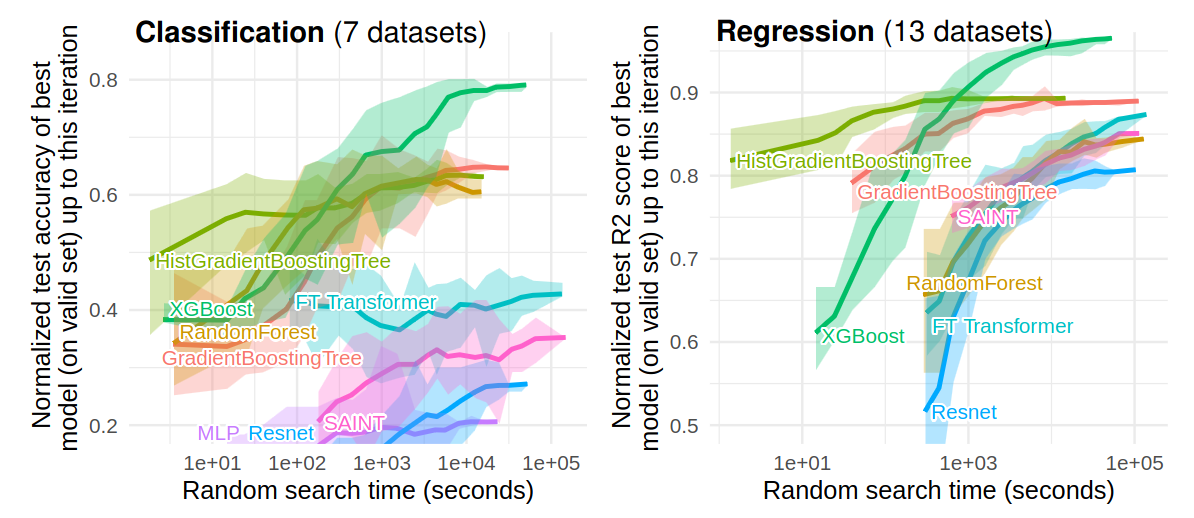
Benchmark comparing models on tabular data while tuning hyper-parameters (from Grinsztajn et al 2023) Each value corresponds to the test score of the best model (on the validation set) after a specific time spent doing random search. The ribbon corresponds to the minimum and maximum scores on these 15 shuffles. Models HistGradientBoostingTree, GradientBoostingTree, and RandomForest come from scikit-learn. FTtransformer, Saint, ResNet and MLP are all deep learning architecture, with FT transformer and Saint models specifically developed for tabular data.
As we can see, scikit-learn’s HistGradientBoosting really shines in terms of good prediction performance for small computational costs. We strive to facilitate datascience: make it lightweight, give good documentation and APIs.
Linear models and tree-based models are there to stay. They answer strong needs for many application settings and they come with small operational cost.
In my opinion, where scikit-learn could really grow to be even more relevant is to integrate better in a broader ecosystem going from databases to putting to production, being more “enterprise ready” :).
Go Top