
We just released skrub 0.2.0. This release markedly simplifies learning on complex dataframes.
model = tabular_learner(‘classifier’)
Simple, yet solid default baseline
The highlight of the release is the tabular_learner function, which facilitates creating pipelines that readily perform machine learning on dataframes, adding preprocessing to a scikit-learn compatible learner. The function packs defaults and heuristics to transform all forms of dataframes to a representation that is well suited to a learner, and it can adapt these transformation: tabular_learner(HistGradientBoostingClassifier()) encodes categories differently than tabular_learner(LogisticRegression()).
The heuristics are tuned based on much benchmarking and experience shows that they give good tradeoffs. The default tabular_learner(‘classifier’) is often a strong baseline.
The benefit are visible in a really simple example:
>>> # First retrieve data >>> from skrub.datasets import fetch_employee_salaries >>> dataset = fetch_employee_salaries() >>> df = dataset.X >>> y = dataset.y >>> # The dataframe is a quite rich and complex dataframe, with various columns >>> df
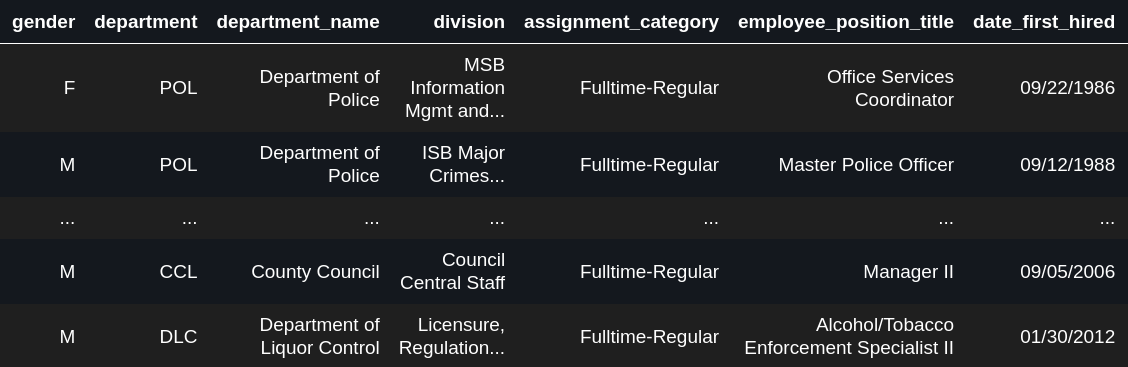
We can then easily build a learner that applies readily to this dataframe, without any transformation:
>>> from skrub import tabular_learner
>>> learner = tabular_learner('regressor')
>>> # The resulting learner can apply all the machine-learning conveniences (eg cross-validation) directly on the dataframe
>>> from sklearn.model_selection import cross_val_score
>>> cross_val_score(learner, df, y)
array([0.89370447, 0.89279068, 0.92282557, 0.92319094, 0.92162666])
transformer = TableVectorizer()
Making encoding complex dataframes easy
Behind the hood, the work is done by the skrub.TableVectorizer(), a scikit-learn compatible transformer that facilitates combining multiple transformations on the different columns of a dataframe. The TableVectorizer is not new in the 0.2.0 release, but we have completely revamped its internals to cover really well edge cases. Indeed, one challenge is to make sure that nothing different or strange happens at test time. Actually, enforcing consistency between train-time and test-time transformation is the real value of skrub compared to using pandas or polars to do transformation.
Increasing support of polars
Short-term goal of optimized support for pandas and polars
We have implemented a new mechanism for supporting both pandas and polars. It has not been applied on all the codebase, hence the support is still imperfect. However, we are seeing increasing support for polars in skrub, and our goal in the short term is to provide rock-solid polar support.
Try skrub out! It’s still young, but in my opinion, it provides a lot of value to tabular learning.