
Note
A simple survey asking authors of two leading machine-learning conferences a few quantitative questions on their experimental procedures.
How do machine-learning researchers run their empirical validation? In the context of a push for improved reproducibility and benchmarking, this question is important to develop new tools for model comparison. We ran a simple survey asking to authors of two leading conferences, NeurIPS 2019 and ICLR 2020, a few quantitative questions on their experimental procedures.
A technical report on HAL summarizes our finding. It gives a simple picture of how hyper-parameters are set, how many baselines and datasets are included, or how seeds are used. Below, we give a very short summary, but please read (and cite) the full report if you are interested.
Highlights The response rates were 35.6% for NeurIPS and 48.6% for ICLR. A vast majority of empirical works optimize model hyper-parameters, thought almost half of these use manual tuning and most of the automatic hyper-parameter optimization is done with grid search. The typical number of hyper-parameter set is in interval 3-5, and less than 50 model fits are used to explore the search space. In addition, most works also optimized their baselines (typically, around 4 baselines). Finally, studies typically reported 4 results per model per task to provide a measure of variance, and around 50% of them used a different random seed for each experiment.
Sample results
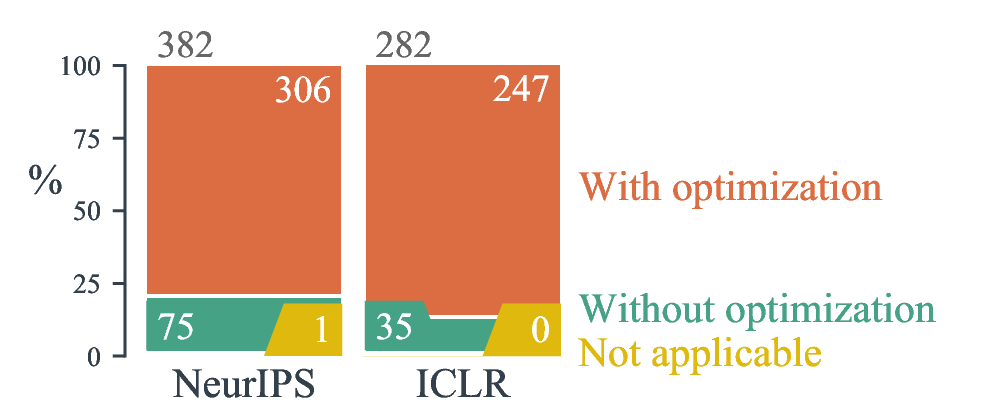
How many papers with experiments optimized hyperparameters.
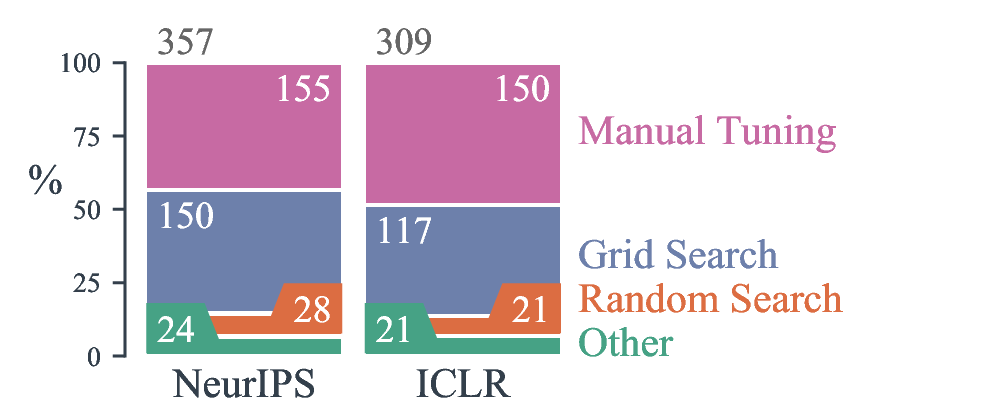
What hyperparameter optimization method were used.
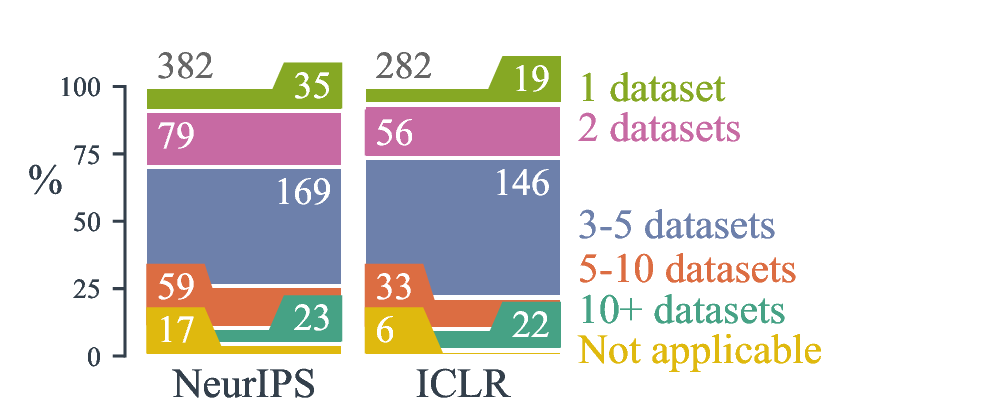
Number of different datasets used for benchmarking.
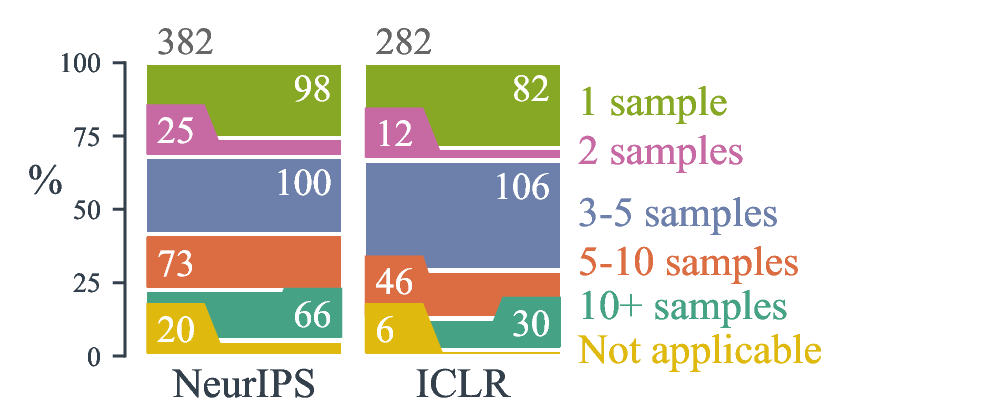
Number of results reported for each model (ex: for different seeds)
These are just samples. Read the full report for more results.
For reproducibility and AutoML, there is active research in benchmarking and hyperparameter procedures in machine learning. We hope that the survey results presented here can help inform this research. As this document is merely a research report, we purposely limited interpretation of the results and drawing recommendations. However, trends that stand out to our eyes are, 1) the simplicity of hyper-parameter tuning strategies (mostly manual search and grid search), 2) the small number of model fits explored during this tuning (often 50 or less), which biases the results and 3) the small number of performances reported, which limits statistical power. These practices are most likely due to the high computational cost of fitting modern machine-learning models.
Acknowledgments We are deeply grateful to the participants of the survey who took time to answer the questions.
Go Top