
We have just released the 0.15 version of scikit-learn. Hurray!! Thanks to all involved.
A long development stretch
It’s been a while since the last release of scikit-learn. So a lot has happened. Exactly 2611 commits according my count. Quite clearly, we have more and more existing code, more and more features to support. This means that when we modify an algorithm, for instance to make it faster, something else might break due to numerical instability, or exploring some obscure option. The good news is that we have tight continuous integration, mostly thanks to travis (but Windows continuous integration is on its way), and we keep growing our test suite. Thus while it is getting harder and harder to change something in scikit-learn, scikit-learn is also becoming more and more robust.
Highlights
Quality — Looking at the commit log, there has been a huge amount of work to fix minor annoying issues.
Speed — There has been a huge effort put in making many parts of scikit-learn faster. Little details all over the codebase. We do hope that you’ll find that your applications run faster. For instance, we find that the worst case speed of Ward clustering is 1.5 times faster in 0.15 than 0.14. K-means clustering is often 1.1 times faster. KNN, when used in brute-force mode, got faster by a factor of 2 or 3.
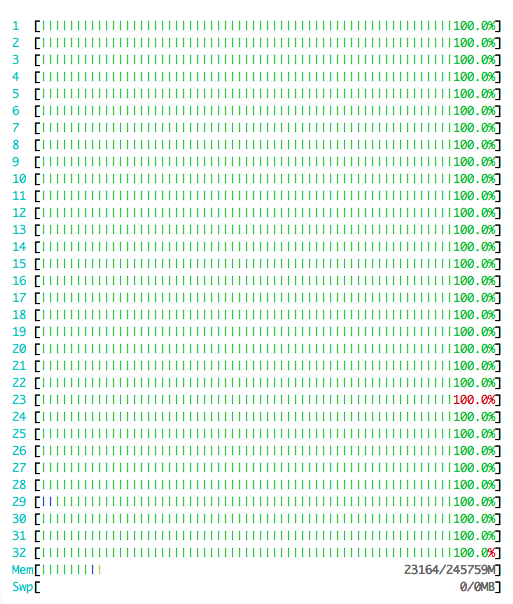
Random Forest and various tree methods — The random forest and various tree methods are much much faster, use parallel computing much better, and use less memory. For instance, the picture on the right shows the scikit-learn random forest running in parallel on a fat Amazon node, and nicely using all the CPUs with little RAM usage.
Hierarchical aglomerative clustering — Complete linkage and average linkage clustering have been added. The benefit of these approach compared to the existing Ward clustering is that they can take an arbitrary distance matrix.
Robust linear models — Scikit-learn now includes RANSAC for robust linear regression.
HMM are deprecated — We have been discussing for a long time removing HMMs, that do not fit in the focus of scikit-learn on predictive modeling. We have created a separate hmmlearn repository for the HMM code. It is looking for maintainers.
And much more — plenty of “minor things”, such as better support for sparse data, better support for multi-label data…